Abstract
The scarcity of task-labeled time-series benchmarks in the financial domain hinders progress in continual learning
and AI algorithm development. Addressing this deficit would foster innovation in this area.
Therefore, we present COB, crude oil benchmark datasets. COB includes 30 years of
asset prices that exhibit significant distribution shifts and comes with corresponding task, or regime, labels based
on these distribution shifts for the three most important crude oils in the world: West Texas Intermediate (WTI),
Brent Blend, and Dubai Crude.
Time-series data pose challenges such as correlatedness, non-stationarity, missing data, and spurious outliers. We
address the problem of out-of-distribution detection and emphasize the relevance of our benchmarks for continual
learning.
Our contributions include creating real-world benchmark datasets by transforming asset price data into volatility
proxies, fitting
models using expectation-maximization, generating contextual task labels that align with real-world events, and
providing these labels to the public.
We hope these benchmarks accelerate research in handling distribution shifts in real-world data, in particular due
to the global importance of the assets represented by the datasets.
Download
Benchmark Datasets with Task Labels
Approach
We meticulously transform, fit the data, and transform the results to obtain labels that partition the data into task, or regimes, based on asset price volatility, a macroeconomic trend that correlates with critical global events, such as economic downturns or recessions.
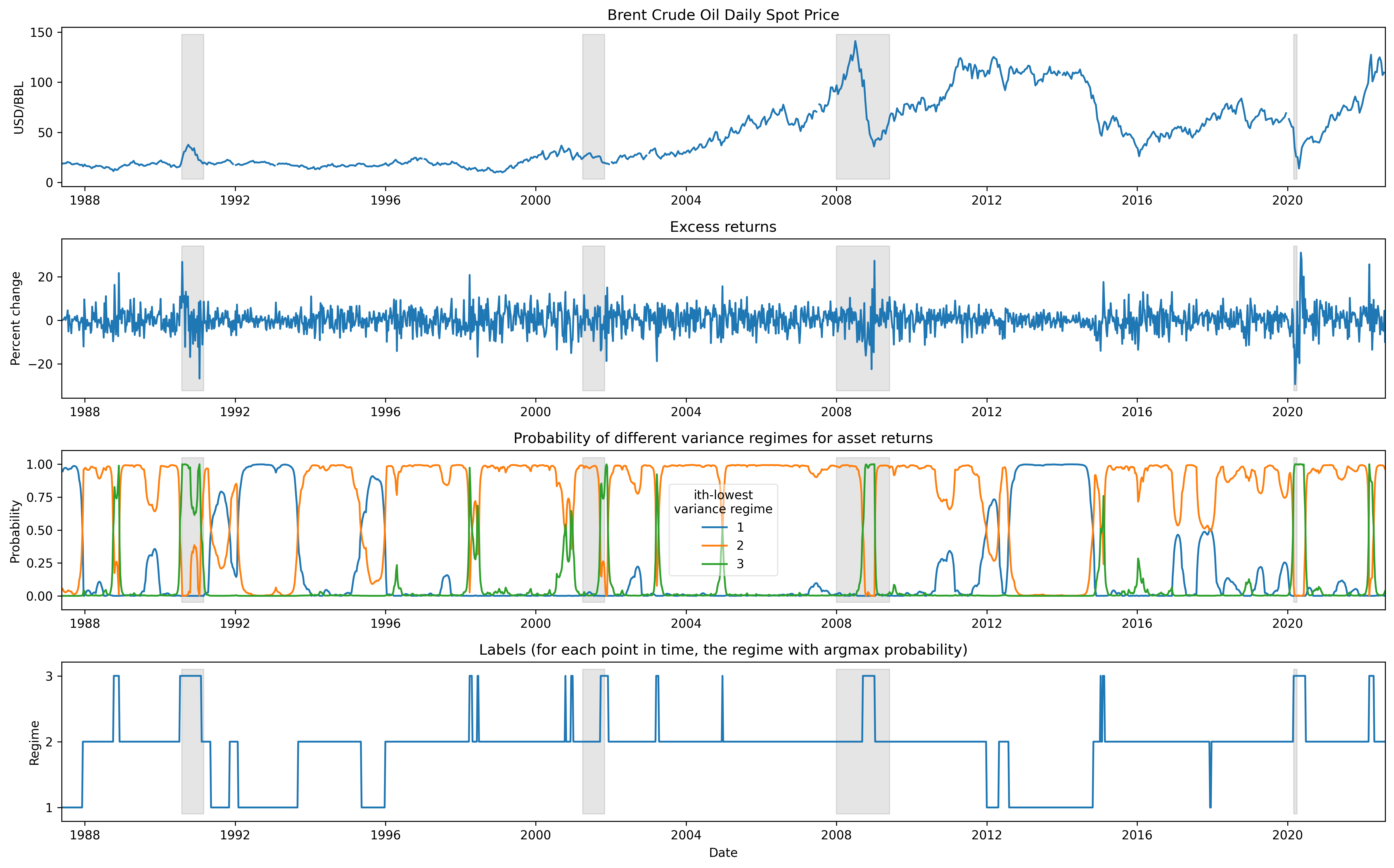
We evaluate four continual learning algorithms: (1) MOLe, (2) MoB, (3) MAML k-shot, and (4) MAML
Continuous on all three datasets.
Two of these algorithms, MoB and MOLe, instantiate new few-shot models adapted from a meta-learned prior. The two
others, MAML k-shot and MAML Continuous use a single model that is adapted from a meta-learned prior.
Results
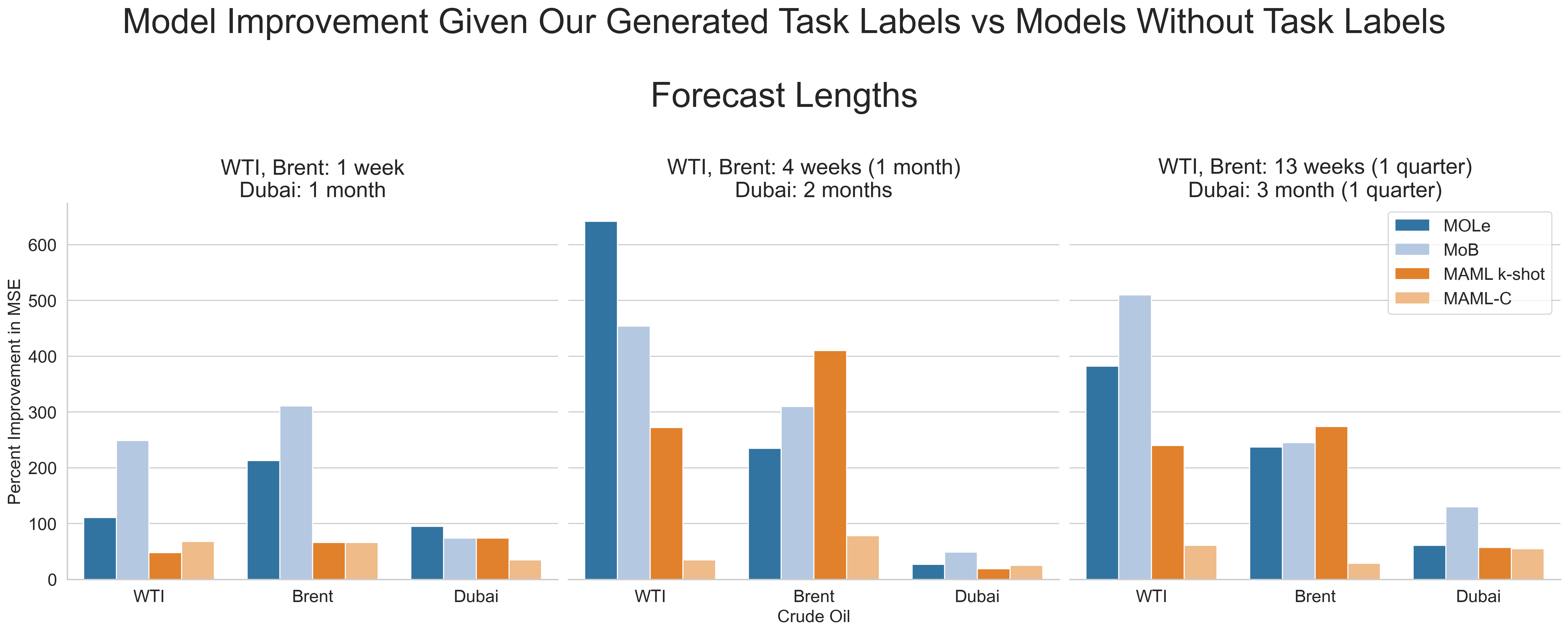
1. The benchmark datasets (WTI and Brent resampled weekly, Dubai remained monthly) and task labels can be downloaded here.2. We report the Percent Improvement in MSE of each algorithm on each benchmark dataset over three Forecast Lengths.
- For WTI and Brent these are 1 week, 4 weeks (1 month), and 13 weeks (1 quarter).
- Since Dubai Crude data is less granular, we use Forecast Lengths 1, 2, and 3 months (1 quarter), respectively.
Conclusion
In conclusion, we have introduced three novel time-series benchmark datasets that encompass the global crude oil
market and generated task labels aligning with significant real-world events, creating a rich context for
further exploration and understanding.
Our goal is to fuel advancements in areas such as continual learning and out-of-distribution detection, while
addressing challenges posed by sequential data.
We believe that these
benchmarks, due to the societal importance of the assets they represent, can make a substantial contribution to AI
research, particularly in handling real-world data that contains distribution shifts.
As AI continues to permeate every sector, the importance of such representative, real-world benchmarks will continue
to grow.